

近日,徐波老师课题组在多模态信息抽取领域的最新研究成果《Label-Enhanced Information Bottleneck Distillation for Multimodal Named Entity Recognition》获ACM Multimedia 2025录用,这是该课题组在此领域的又一重要进展。近三年来,课题组已在相关方向发表CCF A/B类会议论文10余篇。
多模态命名实体识别(Multimodal Named Entity Recognition)作为命名实体识别的重要拓展,结合文本与视觉线索,广泛应用于社交媒体、智能问答和信息抽取等场景。然而,社交平台中大量新词和非规范表达导致现有模型在遇到未见实体时效果显著下降,成为制约技术发展的关键难点。
针对这一挑战,本工作提出了全新的LIBD(Label-Enhanced Information Bottleneck Distillation)框架。相较于现有方法主要依赖外部知识库或简单数据增强的做法,LIBD 首次将“标签增强”与“信息瓶颈蒸馏”相结合:其中教师模型通过双层标签增强(DLA)避免对已知实体的过拟合,学生模型则借助信息瓶颈蒸馏(IBD)精准吸收教师模型的关键信息同时抑制噪声。大量实验显示,LIBD 在Twitter2015 与Twitter2017 两大公开数据集上整体F1 值优于当前SOTA,并在未见实体识别场景中实现显著性能提升。
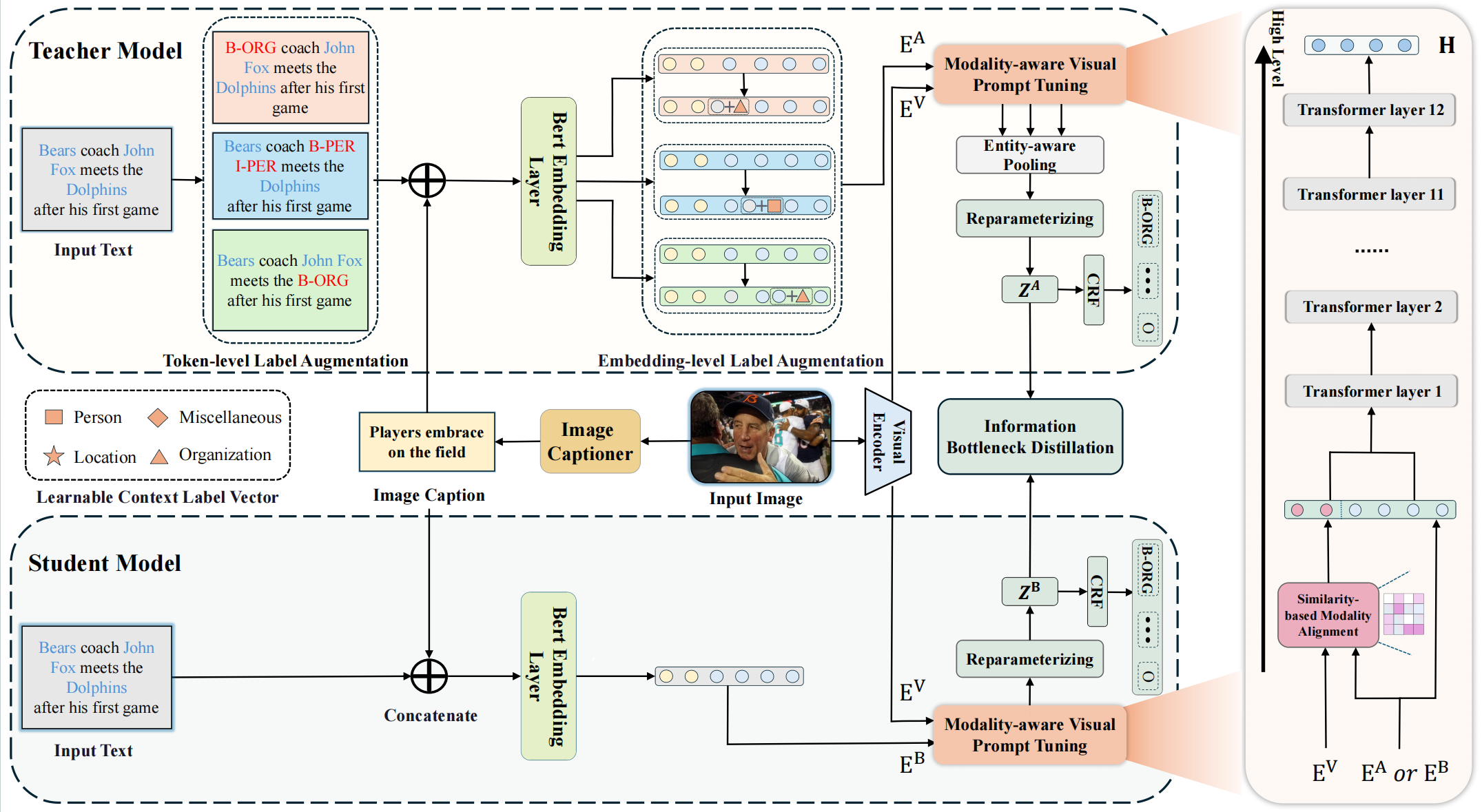
图1. LIBD 流程框架图
ACM Multimedia(ACM MM)由美国计算机协会(ACM)于1993 年创办,是多媒体处理、分析与计算领域的旗舰会议,也是中国计算机学会(CCF)推荐的A 类国际会议,聚焦跨模态内容理解、生成与系统应用等前沿问题,在全球学术界与产业界具有公认的权威性和深远影响力。